
资源编号
18869最后更新
2025-07-09《MOE(Mixture-of-Experts)篇》电子书下载: 这篇文章详细介绍了MOE(Mixture-of-Experts)模型的概念、优势、劣势、并行策略及其在训练和推理中的应用。以下是文章的主……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“《MOE(Mixture-of-Experts)篇》电子书下载”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

《MOE(Mixture-of-Experts)篇》电子书下载:
这篇文章详细介绍了MOE(Mixture-of-Experts)模型的概念、优势、劣势、并行策略及其在训练和推理中的应用。以下是文章的主要内容:
一、为什么需要MOE(Mixture-of-Experts)?
模型和训练样本的增加:导致了训练成本的平方级增长。
提升模型规模:如何在牺牲极少的计算效率的情况下,把模型规模提升上百倍、千倍。
二、MOE(Mixture-of-Experts)的思路是什么样的?
稀疏MoE层:将大模型拆分成多个小模型(专家,expert),在每轮迭代过程中,根据样本数量决定激活一定量的专家用于计算,节省计算资源。
门(gate)机制:引入可训练并确保稀疏性的门机制,以保证计算能力的优化。
计算过程:
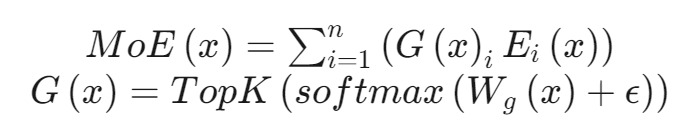
公式解释:对样本x进行门控计算,Softmax处理后获得样本x被分配到各个expert的权重,只取前k个最大权重,最终计算结果是选中的k个专家网络输出的加权和。
三、介绍一下MOE(Mixture-of-Experts)分布式并行策略?
3.1 MOE+数据并行?
门网络和专家网络:都被复制地放置在各个运算单元上。
问题:专家的数量受到单个计算单元(如GPU)的内存大小限制。
3.2 MOE+模型并行?
门网络:复制地被放置在每个计算单元上,专家网络被独立地分别放置在各个计算单元上。
通信操作:需引入额外的通信操作,可以允许更多的专家网络们同时被训练,数量限制与计算单元的数量(如GPU数量)正相关。
侵入性:相较于数据并行+MOE策略,侵入性更强。
四、MoE大模型具备哪些优势?
训练速度更快,效果更好。
相同参数,推理成本低。
扩展性好:允许模型在保持计算成本不变的情况下增加参数数量,扩展到非常大的模型规模,如万亿参数模型。
多任务学习能力:MoE在多任务学习中具备很好的性能(如Switch Transformer在所有101种语言上都显示出了性能提升)。
五、MoE大模型具备哪些缺点?
训练稳定性:MoE在训练过程中可能会遇到稳定性问题。
通信成本:在分布式训练环境中,MoE的专家路由机制可能会增加通信成本,尤其是在模型规模较大时。
模型复杂性:MoE的设计相对复杂,可能需要更多的工程努力来实现和优化。
下游任务性能:MoE由于其稀疏性,使得在Fine-tuning过程中容易出现过拟合。
六、MoE为什么可以实现更大模型参数、更低训练成本?
混合精度方法:用bfloat16精度训练专家,同时对其余计算使用全精度进行。
稀疏路由:每个token只会选择top-k个专家进行计算,减少处理器间的通信成本、计算成本以及存储tensor的内存。
并行优化:可以使用模型并行、专家并行和数据并行,优化MoE的训练效率。
负载均衡损失:提升每个device的利用率。
七、MoE如何解决训练稳定性问题?
混合精度训练。
更小的参数初始化。
Router z-loss:提升训练的稳定性。
八、MoE如何解决Fine-Tuning过程中的过拟合问题?
更大的dropout(主要针对expert)。
更大的学习率。
更小的batch size。
常规手段:目前看到的主要是预训练的优化,针对Fine-Tuning的优化主要是一些常规的手段。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“《MOE(Mixture-of-Experts)篇》电子书下载”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 














还没有评论呢,快来抢沙发~