
资源编号
19112最后更新
2025-07-24《命名实体识别常见面试篇》电子书下载: 这篇文章详细介绍了命名实体识别中的CRF和HMM两种模型的常见面试题目及其相关知识点。以下是文章的主要内容: CRF常见面试题 1……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“《命名实体识别常见面试篇》电子书下载”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

《命名实体识别常见面试篇》电子书下载:
这篇文章详细介绍了命名实体识别中的CRF和HMM两种模型的常见面试题目及其相关知识点。以下是文章的主要内容:
CRF常见面试题
1. CRF的定义与主要思想
• CRF定义:设X与Y是随机变量,P(Y|X)是给定条件X的条件下Y的条件概率分布,若随机变量Y构成一个由无向图G=(V,E)表示的马尔科夫随机场,则称条件概率分布P(X|Y)为条件随机场。
• 主要思想:统计全局概率,在做归一化时,考虑了数据在全局的分布。
2. CRF的三个基本问题
• 定义:给定观测序列x和状态序列y,计算概率P(y|x)。
• 解决方法:前向计算、后向计算。
• 学习计算问题:定义:给定训练数据集估计条件随机场模型参数的问题,即条件随机场的学习问题。公式定义:利用极大似然的方法来定义目标函数。解决方法:随机梯度法、牛顿法、拟牛顿法、迭代尺度法这些优化方法来求解得到参数。目标:解耦模型定义,目标函数,优化方法。
• 预测问题:定义:给定条件随机场P(Y|X)和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)y*,即对观测序列进行标注。方法:维特比算法。
3. 线性链条件随机场的参数化形式
公式:
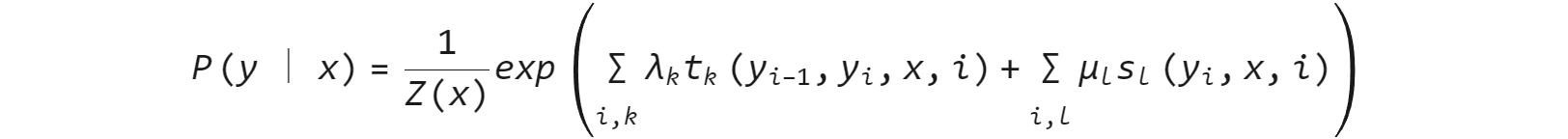
其中,Z(x)是规范化因子,求和是在所有可能的输出序列上进行的。t_{k}是定义在边上的特征函数,称为转移特征,依赖于当前和前一个位置。s_{l}是定义在结点上的特征函数,称为状态特征,依赖于当前位置。
4. CRF的优缺点
• 优点:
为每个位置进行标注过程中可利用丰富的内部及上下文特征信息。
CRF模型在结合多种特征方面存在优势。
避免了标记偏置问题。
CRF的性能更好,对特征的融合能力更强。
• 缺点:
训练模型的时间比ME更长,且获得的模型非常大。在一般的PC机上可能无法执行。
特征的选择和优化是影响结果的关键因素。特征选择问题的好与坏,直接决定了系统性能的高低。
5. HMM与CRF的区别
• 共性:都常用来做序列标注的建模,像词性标注。
• 不同点:
HMM是有向图,CRF是无向图。
HMM只使用了局部特征(齐次马尔科夫假设和观测独立性假设),只能找到局部最优解;CRF使用了全局特征(在所有特征进行全局归一化),可以得到全局的最优值。
HMM是生成模型,CRF是判别模型。
CRF包含HMM,或者说HMM是CRF的一种特殊情况。
6. 生成模型与判别模型的区别
• 生成模型:学习得到联合概率分布P(x,y),即特征x,共同出现的概率。常见的生成模型:朴素贝叶斯模型,混合高斯模型,HMM模型。
• 判别模型:学习得到条件概率分布P(y|x),即在特征x出现的情况下标记y出现的概率。常见的判别模型:感知机,决策树,逻辑回归,SVM,CRF等。
• 区别:判别式模型是根据历史数据中学习到模型,通过提取特征来预测概率;生成式模型是根据特征学习出模型,通过比较概率来确定结果。
HMM常见面试题
1. 马尔科夫过程的定义与核心思想
• 定义:假设一个随机过程中,t_n时刻的状态x_n的条件发布,只与其前一状态x_(n-1)相关,即:
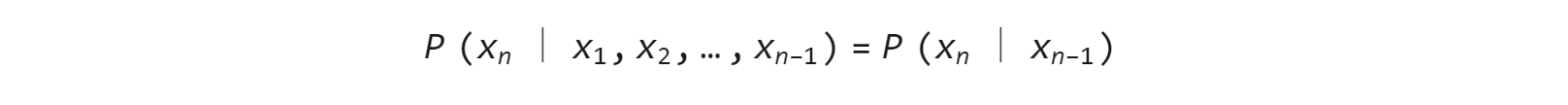
则将其称为马尔可夫过程。
• 核心思想:当前时刻状态仅与上一时刻状态相关,与其他时刻不相关。
2. 隐马尔可夫算法中的两个假设
• 齐次马尔可夫性假设:即假设隐藏的马尔科夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关。
• 观测独立性假设:即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他观测及状态无关。
3. 隐马尔可夫模型的三个基本问题
• 概率计算问题:给定模型(A,B,pi)和观测序列,计算在模型下观测序列出现的概率。(直接计算法理论可行,但计算复杂度太大(O(N^2T));用前向与后向计算法)
• 学习问题:已知观测序列,估计模型参数,使得在该模型下观测序列概率最大。(极大似然估计的方法来估计参数,Baum-Welch算法(EM算法))
• 预测问题:也称为解码问题:已知模型和观测序列,求对给定观测序列条件概率最大的状态序列。(维特比算法,动态规划,核心:边计算边删掉不可能是答案的路径,在最后剩下的路径中挑选最优路径)
4. 三个基本问题的联系
• 渐进关系:首先,要学会用前向算法和后向算法算观测序列出现的概率,然后用Baum-Welch算法求参数的时候,某些步骤是需要用到前向算法和后向算法的,计算得到参数后,我们就可以用来做预测了。因此可以看到,三个基本问题,它们是渐进的,解决NLP问题,应用HMM模型做解码任务应该是最终的目的。
5. 隐马尔可夫算法存在的问题
• 假设的局限性:因为HMM模型简化了很多问题,做了某些很强的假设,如齐次马尔可夫性假设和观测独立性假设,做了假设的好处是,简化求解的难度,坏处是对真实情况的建模能力变弱了。
• 优化方法:在序列标注问题中,隐状态(标注)不仅和单个观测状态相关,还和观察序列的长度、上下文等信息相关。例如词性标注问题中,一个词被标注为动词还是名词,不仅与它本身以及它前一个词的标注有关,还依赖于上下文中的其他词。可以使用最大熵马尔科夫模型进行优化。
关键问题及回答
• 问题1:CRF和HMM在序列标注任务中的具体应用场景有哪些不同?
• 回答:虽然CRF和HMM都常用于序列标注任务,如词性标注,但它们在这些任务中的具体应用场景有所不同。HMM适用于那些可以简化为齐次马尔科夫性和观测独立性的场景,例如语音识别中的音素识别。而CRF则更适合处理复杂的上下文依赖关系,能够捕捉长距离依赖和全局特征,因此在自然语言处理任务中表现更好,如命名实体识别和句法分析。
• 问题2:CRF的参数化形式中,特征函数t_{k}和s_{l}具体是如何定义的?
• 回答:在CRF的参数化形式中,特征函数t_{k}和s_{l}分别定义在边和结点上。转移特征函数t_{k}依赖于当前状态和前一个状态,用于捕捉状态之间的转移概率。例如,在词性标注中,t_{k}可能会考虑当前词的词性和前一个词的词性。状态特征函数s_{l}则依赖于当前状态,用于捕捉当前状态的特定信息。例如,在命名实体识别中,s_{l}可能会考虑当前词的词性或其他语义信息。
• 问题3:隐马尔可夫模型的概率计算问题如何解决?为什么直接计算法不可行?
• 回答:隐马尔可夫模型的概率计算问题可以通过前向计算和后向计算来解决。直接计算法理论上是可行的,但其计算复杂度非常高(O(N^2T)),在实际应用中难以实现。前向计算和后向计算则是通过动态规划的方法,分别从前向和后向计算观测序列在给定模型下的概率,从而将复杂度降低到可接受的范围内。具体来说,前向计算从第一个时间步开始,逐步计算到第T个时间步的概率;后向计算则从第T个时间步开始,逐步计算到第一个时间步的概率。通过这两种计算的结合,可以有效解决概率计算问题。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“《命名实体识别常见面试篇》电子书下载”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 













还没有评论呢,快来抢沙发~