
1B模型秒响应!斯坦福改写推理规则: 斯坦福 Hazy Research 团队刚刚公布了一项重量级优化成果:他们将开源模型 Llama-3.2-1B 的前向推理整合成了一个“Megakernel”……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“1B模型秒响应!斯坦福改写推理规则”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

1B模型秒响应!斯坦福改写推理规则:
斯坦福 Hazy Research 团队刚刚公布了一项重量级优化成果:他们将开源模型 Llama-3.2-1B 的前向推理整合成了一个“Megakernel”,并将低延迟推理能力推向了极限。
在某些实时性极高的应用中,例如对话式 AI 和人类参与的交互式工作流中,大语言模型的响应速度不仅重要,甚至可以决定用户体验的成败。
团队认为限制 LLM 推理速度的瓶颈其实是在内存加载的问题上,他们经过研究发现,现有的开源推理引擎(如 vLLM、SGLang),在极低延迟的单序列生成任务下,即使在顶级 GPU(如 H100)上,也只能利用不到 50% 的内存带宽。
这主要是因为每层 Transformer 模块被拆解成几十到上百个 CUDA kernel,每个 kernel 执行非常小的操作(比如 RMS norm、注意力、MLP、Rotary Position Embedding 等),它们之间存在大量上下文切换与等待。
更严重的是,这些 kernel 启动与收尾的成本加起来,并不会被 CUDA Graph 或 PDL(Programmatic Dependent Launch)等机制充分隐藏,反而在短时任务中被放大。
换句话说,GPU 花了大量时间“等着干活”,而不是“在干活”。Hazy 团队的研究也正是围绕着这个问题展开。
1.Megakernel:从零设计的融合思路
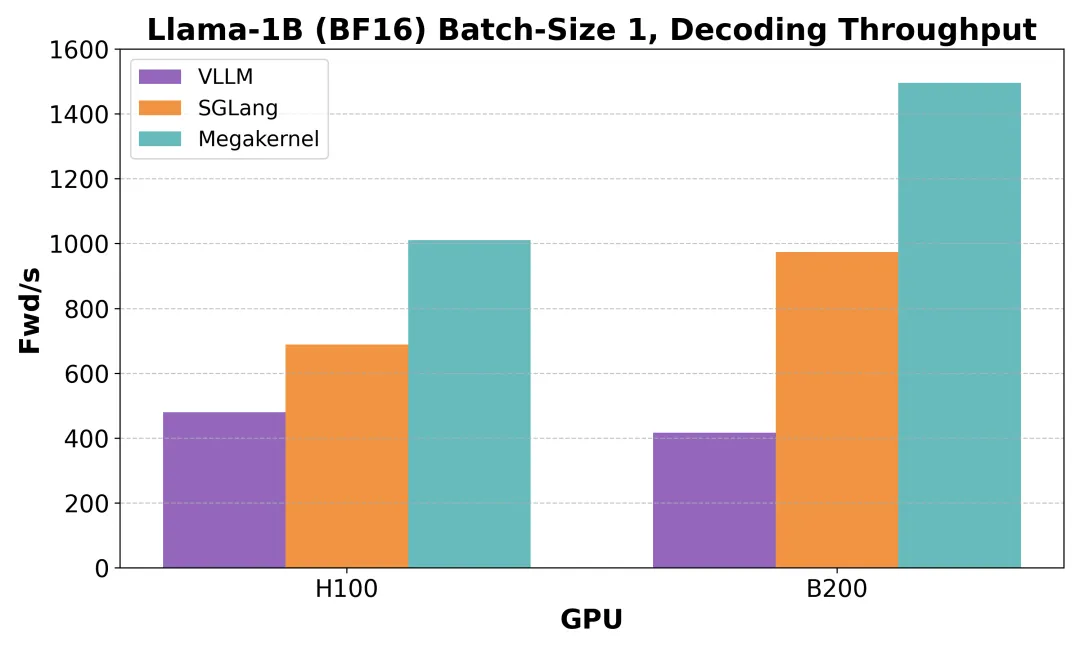
先说实验结果,Megakernel在 H100 上的推理延迟压缩至不足 1 毫秒,显存带宽利用率高达 78%,相较于 vLLM 提升了 2.5 倍、相较 SGLang 提升 1.5 倍;而在更先进的 B200 平台上,延迟进一步降低至 600~680 微秒,逼近理论极限。
从一次完整推理的时间分布来看,250 微秒用于存储激活、等待一致性与数据加载,200 微秒用于 RMSNorm 与 matvec(其中 matvec 占比达 95%),权重加载仅需 30 微秒,流水机制表现稳定。warp 间同步与 barrier 带来 40 微秒的延迟,其余如 setup、参数传递与页状态标记等杂项开销合计约 80 微秒。
整体来看,在精心调度下,Hazy 团队的 Megakernel 几乎已将当前硬件性能压榨至极限。
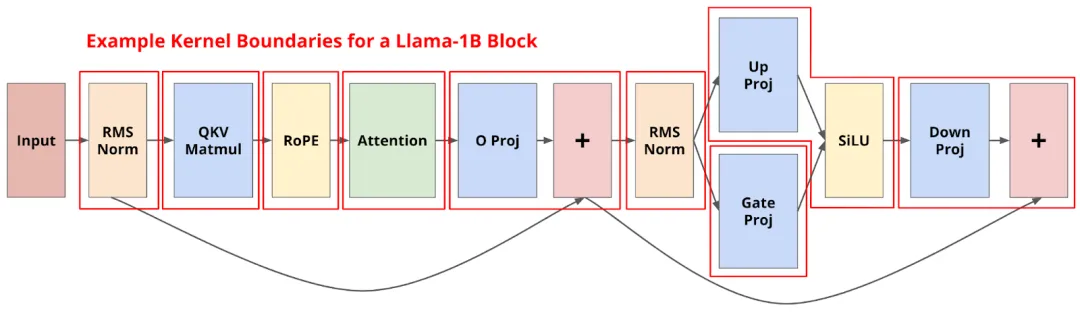
而能够得到以上效果,其实都归功于 Hazy 团队提出的一个激进但有效的设计思路:将整个前向传播过程整合为一个单一 CUDA kernel,也就是所谓的 Megakernel。
实验中,他们基于已有 ThunderMLA 架构,开发了一个 GPU 上运行的轻量“指令解释器”系统。该系统为每个 Streaming Multiprocessor(SM)预先分配一段“执行计划”,其中包含多条按顺序排列的指令,每条指令代表 Transformer 模型中的一个结构单元。
这些指令包括:
• 融合 RMSNorm、QKV projection、RoPE 的复合指令;
• attention 矩阵乘与缩减计算(支持长序列 GQA);
• O-projection 与 residual 相加;
• MLP 的 RMSNorm、gate 激活(SiLU)与上投影;
• down projection 和最终 residual;
• 最后一层 RMSNorm + language modeling head。
每个指令都基于统一的 CUDA 模板构建,实现对 load、store、compute 的标准化封装。指令间依赖由解释器在运行前静态排布,每个 SM 可以重复复用同一个 schedule 以处理多个 token。
此外,为确保高效的数据路径,解释器会将这些执行计划按模型结构静态编排,避免调度时动态分支,提升吞吐与并发执行能力。
同时为了实现流水化计算并防止 shared memory 冲突,团队还对 GPU 的共享内存进行了分页管理,例如:
• 将前 213KB 的 shared memory 分为 13 个 16KiB 页面;
• 剩余部分用于存储指令参数、页分配信息等;
• 每条指令在加载前显示请求页,结束后归还给解释器调度器;
• 当页被释放时,解释器会立即将其分配给下一条等待中的指令。
这种机制保证了下一个计算阶段可以尽早开始预加载权重,从而最大化带宽使用率并消除“气泡”。
不过 Megakernel 结构无法依赖传统的 kernel 间隐式同步,因此 Hazy 团队还使用了一个计数器系统:他们在 global memory 中维护一组整数,每条指令完成后会对对应计数器 +1,若某条指令依赖先前步骤的结果,它会等待计数器达到特定值才执行。
例如:在 MLP 下投影阶段,团队将中间态拆成 4 个 chunk,每个 chunk 在写入后立即触发后续计算,从而实现并行流。此外,团队通过精确设置依赖图,避免了全局 barrier,大幅减少了指令之间等待的浪费,使得整个内核执行尽可能地接近理论并发。
除此之外,研究团队还对 CUDA 异步屏障(asynchronous barrier)的性能进行了测量,发现即便在 barrier 已“pass”的状态下,每次仍需 60ns,同步操作成本不可忽视。而在实际执行中,尤其在 matrix-vector(矩阵乘向量)这类关键操作中,他们发现:在 Hopper 架构(如 H100)上,使用常规 CUDA 核心(非 Tensor Core)可以更有效,不过在 Blackwell 架构上,Tensor Core 性能占优。
这也说明在硬件不同世代中,Megakernel 的最佳实现路径也应适配微架构差异,而非一套方案通用所有平台。
2.为什么传统推理方式效率如此低下?
在详细展开 Megakernel 的构建之前,Hazy 团队其实先回头梳理了一个关键问题:为什么现在主流的 LLM 推理系统,在小 batch、极低延迟这种场景下,表现这么“不给力”。
他们发现,像 vLLM 和 SGLang 这样的系统,在处理生成一个 token 这种极限情况时,GPU 的显存带宽利用率其实非常低。核心原因是——模型前向过程被拆成了太多太小的 CUDA kernel。也就是说,模型里的每一个小操作(比如 RMSNorm、一个 MLP 层)都是一个单独的 kernel。这种“微核模式”,看起来很模块化、易于维护,但其实隐藏了一个很大的性能坑。
每个 kernel 的启动和销毁,其实都有固定成本——你可以把它理解成“换个小任务都要重新开会安排”。在极低延迟场景下,这种“开会”的时间反而成了主开销来源。而且 GPU 在运行这些小 kernel 的时候,还经常会卡在“尾巴”上——比如一个 kernel 要 512 个线程块跑完,但 GPU 只有 148 个执行单元(SM),那后面的线程块就只能排队等前面的慢慢结束,造成很多资源空转。
即便用上 CUDA Graphs、PDL(Programmatic Dependent Launch)等加速器,也还是得花 1.3~2.1 微秒去启动一个 kernel。而这段时间,GPU 其实啥都没干,就是在等待环境切换。更糟的是,由于这些 kernel 是串行排队执行的,后面的 kernel 也没法提前加载它要用的数据,导致 GPU 一直断断续续地访问 global memory,带宽用不上去。
这就形成了所谓的 “memory pipeline bubbles”——计算和计算之间总有空档期,GPU 明明闲不下来,却还是停在那等。举个例子:H100 的带宽是 3.35TB/s,推理 Llama-1B 每次只需要 2.48GB,理论上 1 秒钟能跑 1350 次 forward pass。但因为每层模型得跑 7 个 kernel,一共有 16 层,哪怕每个 kernel 只带来 5 微秒的 stall,总延迟也已经把性能拉到 770 次以内,实际可能还更低。
所以,Hazy 团队很明确地说:这个问题不是哪个 kernel 慢的问题,而是系统性低效。一个个去优化 kernel 其实没有用,核心是要干掉这些 kernel 边界,别再让 GPU 一会做这个、一会做那个地切换。这就是他们提出 Megakernel 的根本动因。
现代 LLM,动辄几十上百层 transformer,每层又包含 RMSNorm、注意力、MLP 等等操作。主流框架为了清晰易调试,把这些都拆成一个个小 kernel,每个做一件小事,像流水线上的工人。但问题是,这流水线换手太频繁,每次“换人”都耽误事,还导致 GPU 的显存访问老是断断续续,带宽效率拉垮。
更要命的是,CUDA 的一些机制虽然看起来是为优化服务的,但在这种极限场景下其实也成了“绊脚石”。比如 PDL 的 cudaGridDependencySynchronize 会强制等所有任务完成才能继续,这就意味着,即便有些任务早就准备好了,也得一起等着。
所以归根结底,现在的推理系统架构,在“单序列、毫秒级响应”这类场景下,是低效的,而且是从系统层面低效。只有重构整个执行方式,让 GPU 少切换、多并行,才有可能真正把它的算力榨干,这正是 Megakernel 的价值所在。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“1B模型秒响应!斯坦福改写推理规则”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~