
从CoT到“思维固化”:大模型为何越训越笨?: 从 ChatGPT 发布以来,大语言模型就引发了市场和科研领域的巨大的关注,其中绝大部分兴奋都源于大模型的涌现特性:它们……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“从CoT到“思维固化”:大模型为何越训越笨?”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

从CoT到“思维固化”:大模型为何越训越笨?:
从 ChatGPT 发布以来,大语言模型就引发了市场和科研领域的巨大的关注,其中绝大部分兴奋都源于大模型的涌现特性:它们似乎能够回忆训练中的信息,编写代码,并且进行逻辑推理。人们期望大模型能借助推理能力在会计、编程等领域拓展专业知识、减少重复性任务,为未来的职业生活提供协助。
但从现有的大模型推理能力评估来看,这些基准虽然涵盖自然语言处理、推理、编码和数学能力等多个领域,各类排行榜也聚焦于模型在特定任务上超越当前 SOTA 水平的表现,多关注答案正确性而非推理步骤的准确性。
为此,在一篇名为“Large Language Models’ Reasoning Stalls: An Investigation into the Capabilities of Frontier Models”的论文中,研究人员 Lachlan McGinness、Peter Baumgartner 等提出一项纵向研究,追求更加全面地衡量大模型的推理能力。
研究根据截至 2023 年 12 月和 2024 年 8 月表现最好的大模型在 PRONTOQA 逻辑推理基准上的表现,对大模型的推理能力进行了评估,测试的 SOTA 模型包括 GPT3.5 Turbo、GPT-4 和 GPT-4o、Gemini-Pro、Claude 3 Opus 和 Llama3.1 405B。

论文地址:https://arxiv.org/abs/2505.19676
1.正确答案≠正确推理
当前多数模型推理能力评估聚焦于大模型在各类基准测试中的答案准确性,如自然语言处理、推理、数学能力等领域的任务,却忽视推理步骤的正确性,且未充分考虑结果的不确定性:模型可能通过 “记忆猜测” 等捷径而非逻辑推导得出结论,导致单一的准确率无法全面衡量其推理能力。
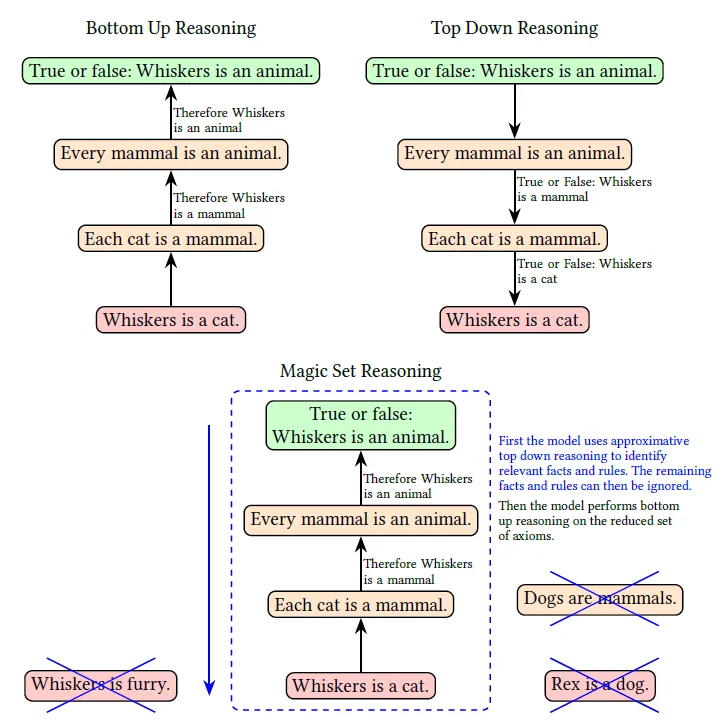
在推理策略方面,自动定理证明(ATP)领域的自底向上(正向链)、自顶向下(反向链)等策略已被用于提升推理效率,但大模型能否通过上下文学习有效应用这些策略仍需验证。
此外,现有研究多聚焦单一时间点的模型对比,缺乏对同一基准上模型能力随时间变化的纵向分析,例如 GPT-4 到 GPT4-o 的推理能力是否实质性提升等。
为了从多维度评估大模型推理能力的真实表现,研究人员围绕大模型在 ATP 推理策略下的能力评估展开,通过多维度实验设计、自动化数据解析与统计分析,系统探究模型推理的准确性与过程忠实性。
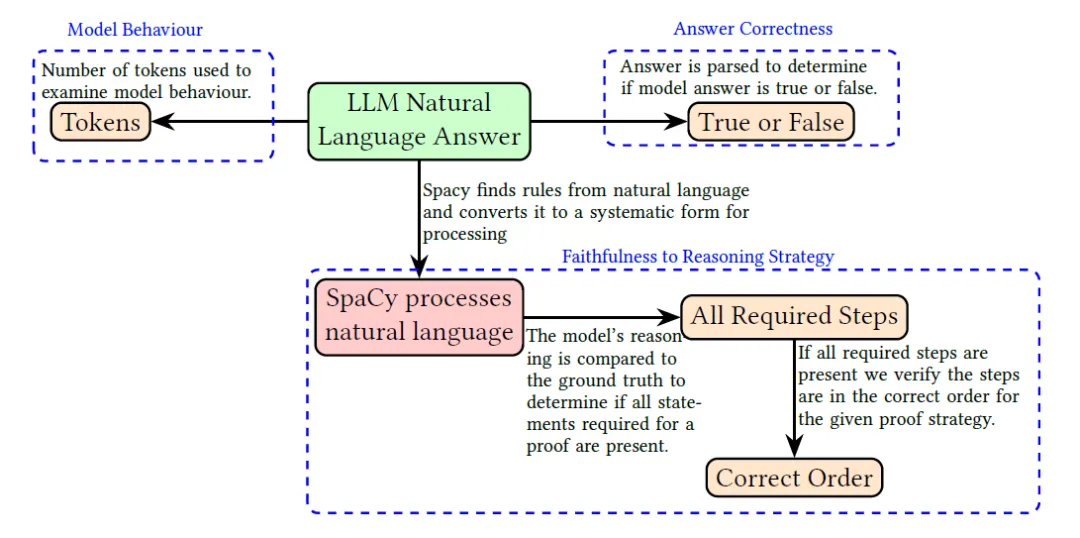
具体来看,研究选取 2023 年 12 月与 2024 年 8 月的前沿模型,包括 OpenAI 的 GPT-3.5 Turbo、GPT-4、GPT4-o,Google 的 Gemini-Pro,Anthropic 的 Claude 3 Opus(经验证优于 Claude 3.5 Sonnet),以及 Meta 的 Llama3.1 405B,使用 PRONTOQA 逻辑推理基准进行测试。
PRONTOQA 基准以问题生成器形式发布,避免了数据污染问题,且支持通过生成任意数量的问题进行统计分析和不确定性测量,同时该基准不常被用作评估指标,可降低模型过拟合的可能性,为评估大模型的推理过程提供了可靠场景。
实验设计 6 种提示策略:基准(Normal)、零样本链思维(Zero-shot CoT)、单样本链思维(One-shot CoT)、自底向上推理策略(Bottom Up)、自顶向下推理策略(Top Down)及魔术集转换策略(Magic Set Transformation),每种策略对每个模型进行 1800 次调用(3 种推理步骤 ×100 次 / 步骤 ×6 种提示),确保数据量充足。
2.模型推理能力发展停滞
研究结果显示,实验选取的大模型的推理能力提升陷入停滞,GPT-4o、Claude Opus 等前沿模型在多数实验条件下的表现未显著超越 2023 年的 GPT-4,前者的进步主要归因于提示词工程与自动应用思维链(CoT)进行训练,而非模型架构或训练数据的实质性改进。
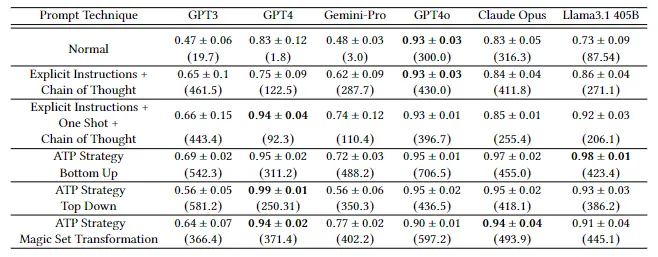
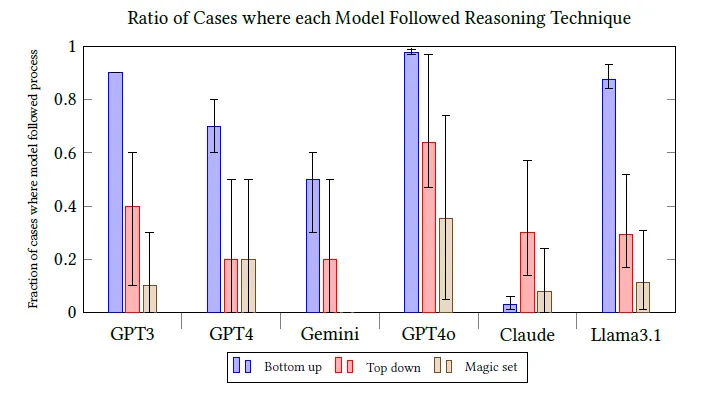
所有模型在自底向上推理策略下准确率最高且最能忠实遵循推理步骤,综合表现最佳;自顶向下和魔术集转换策略因复杂度较高,模型难以有效执行,表现较差。
从实验数据来看,不同模型在遵循推理策略的能力上存在显著差异,如 Claude Opus 因规则与事实顺序颠倒导致自底向上策略忠实度低;诸如魔术集转换等复杂策略执行一致性普遍偏低,说明大模型对结构化推理流程的理解仍有限。
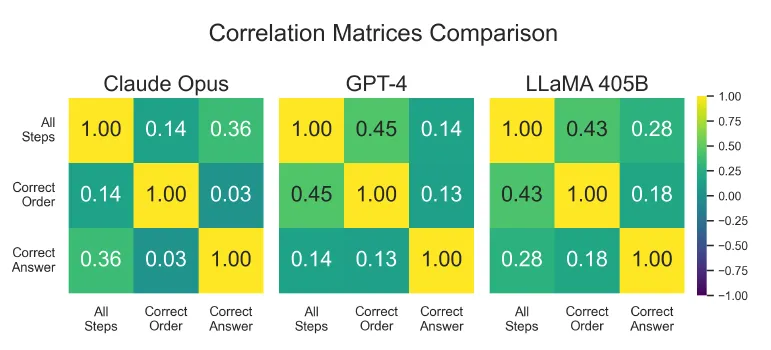
此外,通过皮尔逊相关系数分析发现,正确推理步骤的完整性和顺序忠实性与答案正确性仅存在低正相关性,Claude Opus 的 “正确答案” 与 “完整推理步骤” 相关性仅为 0.14,说明大模型可能通过记忆或猜测而非逻辑推理得出结论,推理过程的可靠性有限。
且 2024 年模型在基准条件下的 token 使用量显著增加,GPT-4o 的完成 token 数为 300.0,Claude Opus 为 316.3,远超 2023 年 GPT-4 的 1.8,表明其已被训练为默认启用 CoT 推理,而 Llama3.1 405B 因未使用隐藏提示,推理步骤完整性较低,基准条件下推理步骤完整性仅为 0.73±0.09,也进一步验证了 prompt 工程对模型表现的影响。
综合实验数据,2023 至 2024 年间大模型推理能力的提升主要可以归因于提示工程(如内置 CoT),而非模型架构优化,新模型在复杂推理场景中并未超越 GPT-4,自底向上策略因逻辑清晰、易于遵循,成为大模型最有效的推理方式,而自顶向下与魔法集转换策略因复杂度高,应用受限。
大模型推理能力出现停滞现象,提升已进入瓶颈期,进步主要依赖提示工程而非模型自主推理能力的突破,而自底向上策略虽为最优实践,但模型仍缺乏可靠的逻辑链条生成能力。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“从CoT到“思维固化”:大模型为何越训越笨?”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~