
AI绘画手把手教你用stable diffusion绘制真人图像: 首先我们要在本地部署stable-diffusion,网上有很多小白教程,这里我就不多赘述了,我们直接上使用教程。 1、到stab……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“AI绘画手把手教你用stable diffusion绘制真人图像”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

AI绘画手把手教你用stable diffusion绘制真人图像:
首先我们要在本地部署stable-diffusion,网上有很多小白教程,这里我就不多赘述了,我们直接上使用教程。
1、到stable-diffusion目录下找到webui-user.bat这个文件,双击打开它,有的安装包里管它叫“启动器”,总之,打开就行。
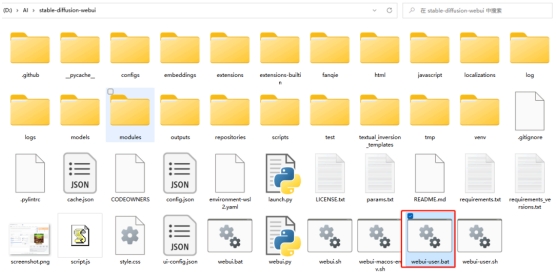
双击打开它
2、接着,你会看到一个大黑框,不要管它,等一会看到出现“To create a public link, set `share=True` in `launch()`.”,就说明启动完成,这个框不要关(重要的事情说三遍:不要关!不要关!不要关!)
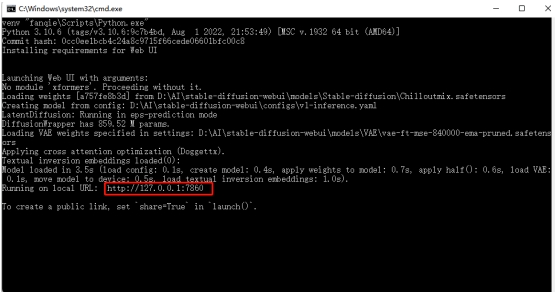
复制红框内的地址,在浏览器中打开
3、复制红框内的的地址(http://127.0.0.1:7860),在浏览器中打开,便出现了 stable-diffusion-webui 的操作界面。
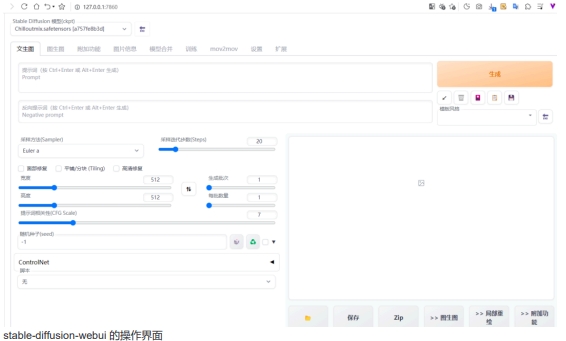
stable-diffusion-webui 的操作界面
4、下面我们主要讲解一下红框内我标示出来的几个区域,分别是模型区、提示词区、反向提示词区。
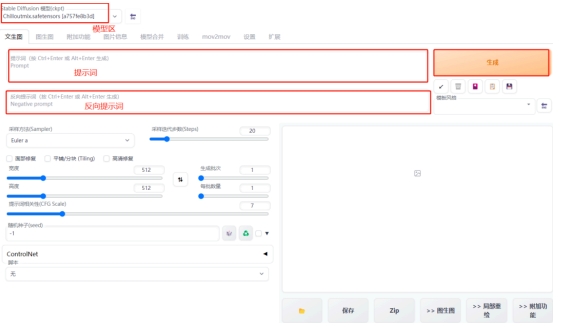
模型区:stable-diffusion 生成图像时主要依据的大模型,一般在本地部署好后会自带一个,我这里用的是非常有名的真人模型 chilloutmix ,用它可以生成照片级的人物图片。如果没有这个模型,可以到网上下载。
提示词区:SD会依据我们输入的文字生成图片,比如我们输入“一个坐在椅子上的小女孩”,AI就会依据这个词语进行生成图片。提示词越丰富,细节越多,越能达到自己的要求。注意,提示词要用英文写,每个提示词用英文逗号隔开。
反向提示词区:把自己不想出现的词语输入在里面,比如“大脸蛋,三只手”等。
生成按钮:提示词输好后,点击生成按钮,AI就会根据我们的要求自动生成图片啦。
5、这是我用提示词生成的图片。提示词的用法,下次再介绍,不会用的可以照我的抄一下。
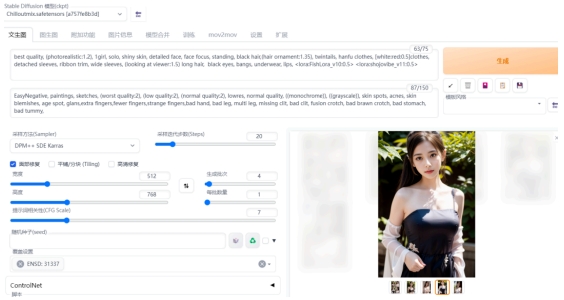
不会写提示词的,可以照我的抄一下。
6、最后放几张成品照。

嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“AI绘画手把手教你用stable diffusion绘制真人图像”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~