
AI配音-AI声音模型+数字人语音驱动,可以把视频搞得有声有色: 刚过去的这个周末,刚好遇到高考,然后就想着搓个有趣的卡通动画,给高考学子加油一下。发现效果挺不错的……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“AI配音-AI声音模型+数字人语音驱动,可以把视频搞得有声有色”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

AI配音-AI声音模型+数字人语音驱动,可以把视频搞得有声有色:
刚过去的这个周末,刚好遇到高考,然后就想着搓个有趣的卡通动画,给高考学子加油一下。发现效果挺不错的,索性就多弄了2个语音克隆,发个文章记录一下。
看看效果
用的是海螺MiniMax的Speech-02-hd + 腾讯混元的数字人语言驱动模型HunyuanVideo-Avatar,大家直观的感受一下,Speech-02的语音合成能力有多强。
我就扔了一段30秒的原声进去复刻,说实话,这音调,这起伏,这音色,真的感觉真假难分。
现在,这个新模型,MiniMax Speech-02-hd,已经可以在MiniMax官网用了,目前只有海外版有声音克隆,别问我为什么只有海外版有。
网址在此:https://www.minimax.io/audio
语音克隆如何使用
进入Minimax的Audio官网后,点击左边的Voices。
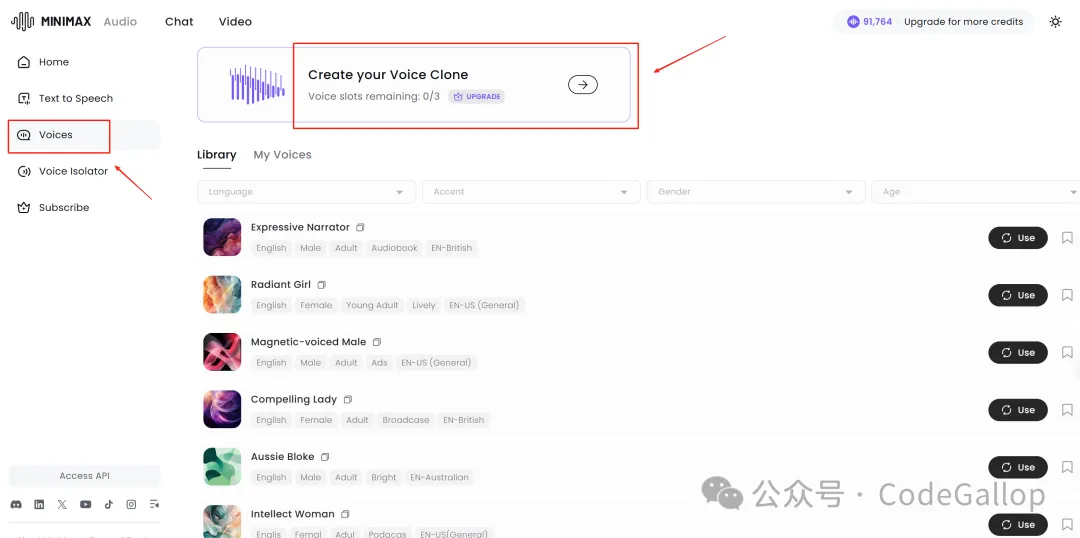
免费用户,可以免费克隆3个声音。
我花了3美元买了10万的credits,应该有百来分钟的语音合成。
点进去以后,直接上传你的素材,然后正常命名,选择主语言就行,很简单。
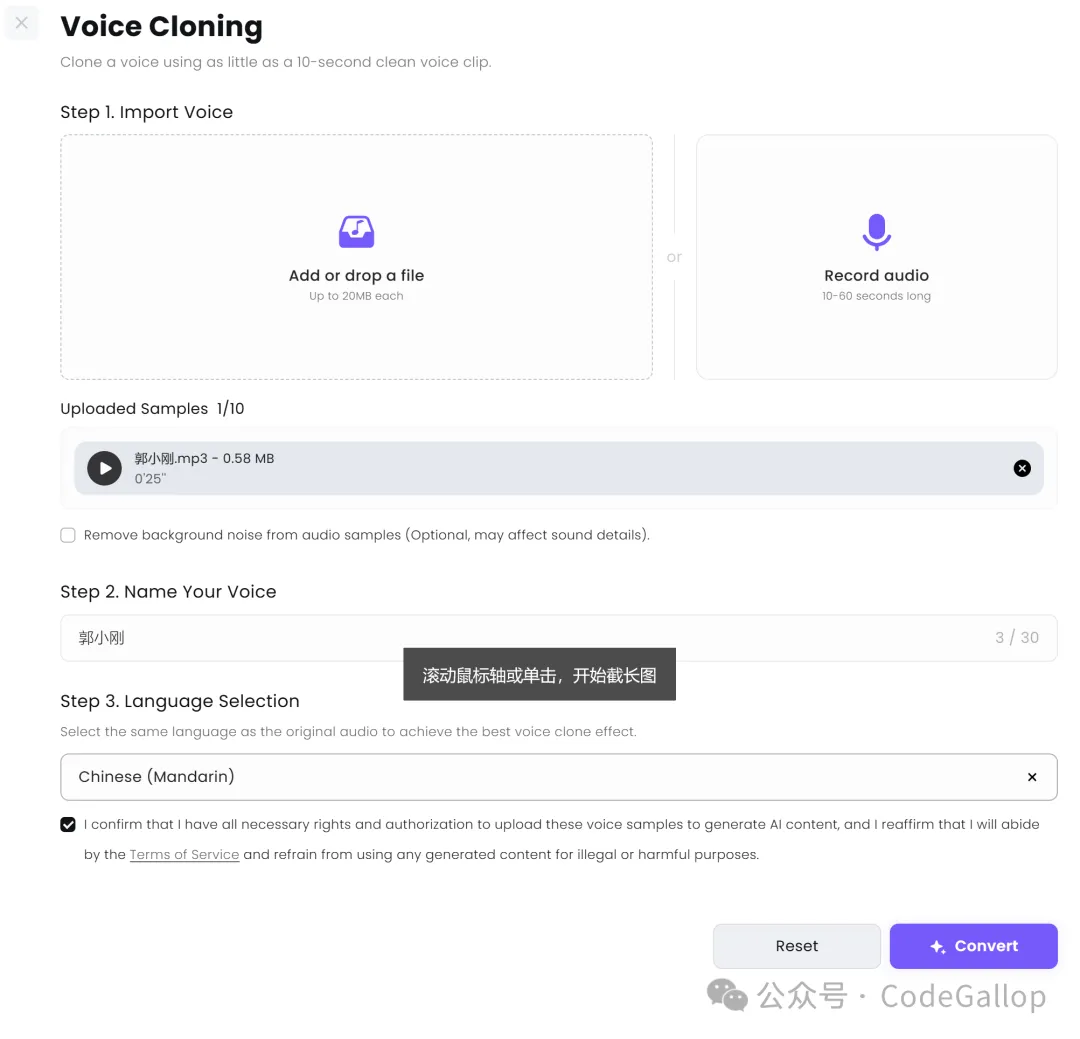
上传的语音最少上传10s的音频片段就可以克隆了,不过这个样本其实不是特别够,所以我一般推荐音频素材最好在30s左右。
然后只需要十几秒,一个新鲜的声音模型,就克隆好了。
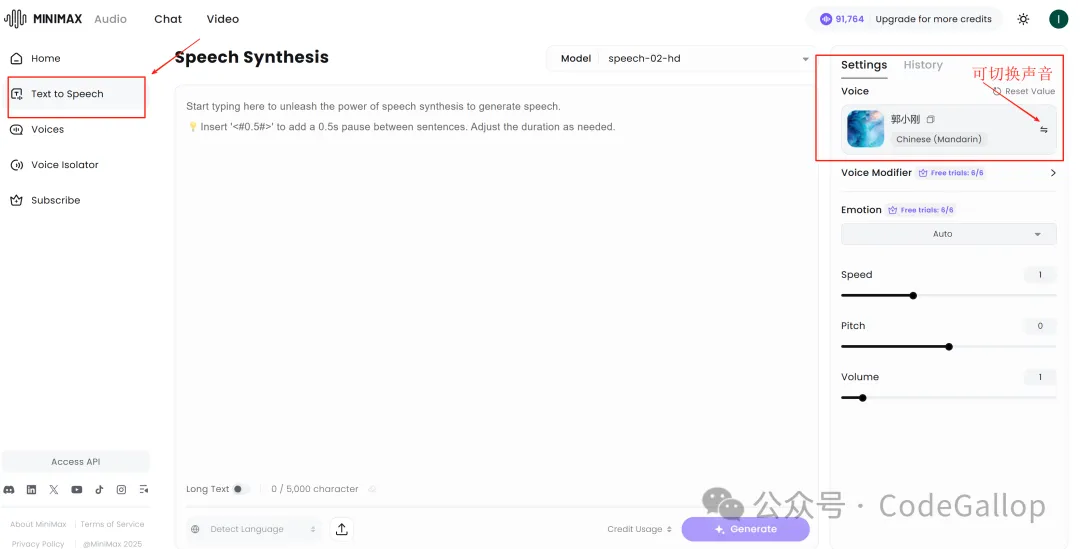
后续使用的时候,直接在右边的声音选择界面里面找到自己的tab,正常使用就行。
数字人语音驱动如何使用
视频生成用到了来自腾讯混元发布并开源的语音数字人模型HunyuanVideo-Avatar。
用户可上传人物图像与音频,HunyuanVideo-Avatar模型会自动理解图片与音频,比如人物所在环境、音频所蕴含的情感等,让图中人物自然地说话或唱歌,生成包含自然表情、唇形同步及全身动作的视频。
体验入口:https://hunyuan.tencent.com/modelSquare/home/play?modelId=126
使用非常的方便,上传音频及一张图片,就可以驱动生成相应的视频。
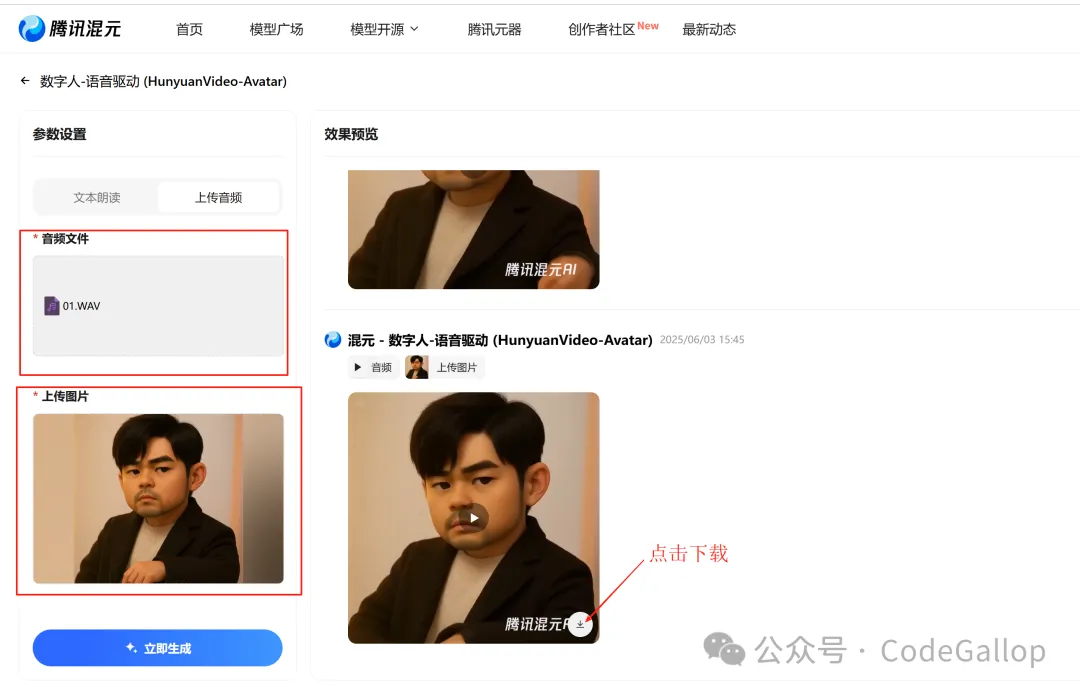
音频需要是WAV格式的,目前只支持14秒的音频,所以如果你要生成比较长的视频,可以把音频切割成几段,分别生成视频,再进行拼接。
多语种混合尝试
目前海螺的Speech-02-hd 已经支持32种语言,为了测试其他语言的音频生成,我搞了一个比较复杂的,甄嬛传的皇四郎。
文本是这样的:
妈的,开个周会而已,至于吗?
负责人(突然拍桌):
“Listen team, we need to optimize the workflow as soon as possible”
(突然摸下巴切换法语)
“Ah oui, et rajoutez une touche de créativité, s’il vous plaît~”
(转向我,切日语)
「これはマジでイラっとするわ〜」
(突然拍大腿切西语)
“¡Caramba! ¿No hay nadie aquí que entienda el valor de la eficiencia?”
(我默默打开翻译软件,他又切德语扶眼镜)
“Entschuldigt, aber ich finde, wir sollten first prioritieren…”
我(拍桌,中文暴走): 你是在玩语言接龙吗?!到底说人话还是 ——
众人(摔笔): 所以刚才那堆「c’est la vie」「santé」都是 AI 在装逼?!
哦,他是 MiniMax Speech two,新模型。
真的,实在太好玩了。
很有趣的是,他们在讲故事的场景中,如果你只用一个声音的话,在一些不同角色那里,它甚至会有不同的音调变化和情绪变化。
说说使用感受
目前海螺的Speech-02-hd 语音合成模型,使用起来感受很好,而且也很顺滑,它会根据提供的文本内容会有不同的音调变化和情绪变化,语音克隆还原度也非常的高。我用了几次就爱上了,现在已经开始充值使用了。
要说不足,就是对某些语境的理解还是需要加强,比如我想让它合成如下这段文字的语音:
“厦门的佛教文化氛围浓厚,阿公阿嬷们每逢初一十五都有去寺庙拜拜”
这里面的“阿嬷”讲出来就没有闽南的味道,发音也不太对,还有“拜拜”直接读成“bye bye”的声音,正确的读法应该是第四声。
不管怎样,在普通话的表现已经让人很惊喜了。
另外,视频的生成,因为每次只能生成14秒的视频,想要生成长视频,就得分段生成,再拼接,这样拼接处,就会有跳帧的感觉,不知现在有没有人去开发个AI agent ,专门处理视频无痕拼接的功能,这对视频剪辑的人应该是一个强烈的需求。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“AI配音-AI声音模型+数字人语音驱动,可以把视频搞得有声有色”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 














还没有评论呢,快来抢沙发~