
千问团队开源图像基础模型 Qwen-Image: 千问大模型团队 最近开源了 Qwen-Image,一个图像基础模型。Qwen-Image 支持从文本到图像(T2I)的生成任务以及从文本图像到图……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“千问团队开源图像基础模型 Qwen-Image”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

千问团队开源图像基础模型 Qwen-Image:
千问大模型团队 最近开源了 Qwen-Image,一个图像基础模型。Qwen-Image 支持从文本到图像(T2I)的生成任务以及从文本图像到图像(TI2I)的编辑任务,并且在多项基准测试中均取得了超越其他模型的卓越表现。
Qwen-Image 使用 Qwen2.5-VL 处理文本输入,使用变分自编码器(VAE)处理图像输入,并通过多模态扩散变换器(MMDiT)进行图像生成。这一组模型在文本渲染方面表现出色,支持英语和中文文本。千问团队在包括 DPG、GenEval、GEdit 和 ImgEdit 在内的 T2I 和 TI2I 基准测试中对模型进行了评估,Qwen-Image 总体得分最高。在图像理解任务中,尽管不如专门训练的模型表现好,但 Qwen-Image 的性能与它们“非常接近”。此外,千问团队还创建了 AI Arena,一个比较网站,人类评估者可以在上面对生成的图像对进行评分。Qwen-Image 目前排名第三,与包括 GPT Image 1 在内的五个高质量闭源模型竞争。根据千问团队的说法:
Qwen-Image 不仅仅是一个最先进的图像生成模型,更是多模态基础模型领域的一次范式转变。它不仅在技术基准上取得了卓越成就,更挑战着整个社区重新思考生成模型在感知、界面设计和认知建模中的角色……随着我们持续扩展和完善这些系统,视觉理解和生成之间的界限将愈发模糊,为真正交互式、直观且智能的多模态智能体铺平道路。
为了创建模型的训练数据集,千问团队“收集并标注了数十亿对图像文本对”。其中图像涵盖了四个主要类别:自然、设计、人物和合成数据。自然图像约占数据的 55%。设计图像(包括绘画、海报和 GUI 图像)约占数据的 27%,并且包含了许多具有“丰富文本元素”的图像。这个初始数据集经过了大量筛选,去除了低质量的图像。他们还设计了一个标注框架,为每张图像生成详细的标题和元数据。
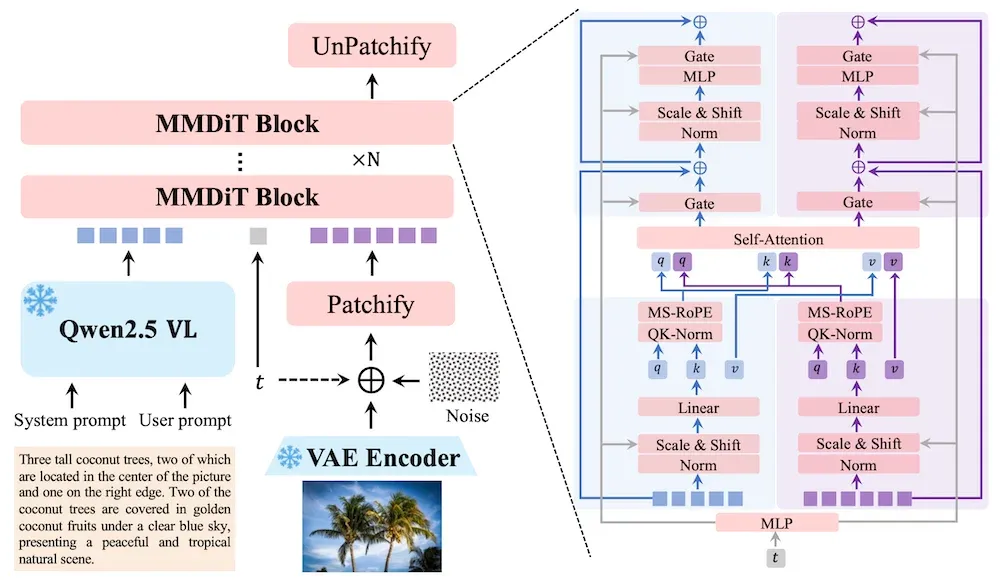
千问团队设计了一个预训练过程,采用多种策略逐步改进模型的输出。团队采用了一种逐步提升图像分辨率的策略,将图像从 256×256 像素放大至 640×640,再到 1328×1328 像素。其他策略包括引入包含渲染文本的图像、具有更多样化领域和分辨率分布的图像,以及具有“超现实风格或……大量文本内容”的合成图像。
最后,模型的后训练分为两个阶段。第一阶段是监督微调(SFT),使用“精心人工标注”的数据集生成详细且逼真的图像。第二阶段是强化学习(RL),采用两种不同的策略优化方法,模型根据给定的提示词生成多张图像,由人类评估者挑选出最好和最差的图像。
Hacker News 的用户普遍对模型的表现给予了高度评价,并将其与 gpt-image-1 进行了对比。其中一位用户对此次发布表示:“这似乎意义重大。”另一位用户写道:
除了风格转换、对象添加和删除、文本编辑、人物姿态操作外,它还支持目标检测、语义分割、深度 / 边缘估计、超分辨率和新视角合成(NVS),即从基础图像合成新视角。它就像一个功能强大的“多面手”!初步结果显示,gpt-image-1 在清晰度和锐度方面略胜一筹,但我不确定 OpenAI 是否只是在后处理步骤中做了一些基本的锐化处理?
Qwen-Image 的代码可在 GitHub 上找到,模型文件 可以从 Huggingface 下载。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“千问团队开源图像基础模型 Qwen-Image”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~