
32B模型横扫SWE任务,这款代码智能体模型有点东西: 2025年不仅是智能体爆发元年,也是AI软件工程的元年。以AI驱动的自动化软件工程正加速重构开发范式。 今天昆仑万维……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“32B模型横扫SWE任务,这款代码智能体模型有点东西”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

32B模型横扫SWE任务,这款代码智能体模型有点东西:
2025年不仅是智能体爆发元年,也是AI软件工程的元年。以AI驱动的自动化软件工程正加速重构开发范式。
今天昆仑万维官宣,开源代码智能体Skywork-SWE-32B今日全球上线,以“小参数”重写仓库级修复规则。
这是开源生态对抗闭源巨头的关键一役——Skywork-SWE-32B让企业用消费级显卡部署AI工程师成为现实。
模型在SWE-bench-Verified上(OpenHands代码辅助框架)将修复准确率拉升至47.0%,一举超越了现有参数规模在32B以下的开源模型,直逼Claude v3.7(56.0%)的闭源神话。
挣脱了闭源的枷锁,AI正从“工具”升级为“协作者”,软件工程才能真正迎来智能体驱动的范式转移。
现在,开发者可在Hugging Face领取这份“开源工程师”了。
技术报告:https://huggingface.co/Skywork/Skywork-SWE-32B/resolve/main/assets/Report.pdf
博客:https://quixotic-sting-239.notion.site/eb17f379610040ceb54da5d5d24065bd
模型权重:https://huggingface.co/Skywork/Skywork-SWE-32B
SWE任务:对智能体模型的终极试炼
经常写代码的人都知道,软件工程(Software Engineering, SWE)任务,可以说是难度远超一般的代码生成任务。将大型语言模型驱动的智能体投入真实的软件工程任务,绝非简单的“写代码”指令所能涵盖。
即使是人类工程师,处理陌生项目时首次修复正确率也不到70%。
现在,将一个SWE任务交给智能体模型,简直像是要求一个“AI工程师”在极短的时间内,快速融入一个新团队接手一个庞大且不熟悉的遗留系统,准确理解一个模糊的Bug报告,找到根本原因,设计出符合团队规范且不会破坏任何其他功能的修复方案,并一次性提交正确的代码变更。
这样的“AI工程师”可真不好找。
超越传统代码生成的能力要求
和传统的代码生成相比,SWE的要求可谓是高得离谱。任何一个环节的薄弱,都可能导致智能体在复杂工程现实面前束手无策。
以上下文范围问题为例吧。代码生成关注语法和局部逻辑,就像只看见一棵树;而软件工程需要理解整片森林的生态系统。
说到修改某个函数时,普通生成器只看函数本身,工程师却要考虑十处调用点和三年前留下的TODO注释。非技术层面更关键,那些从未写在代码里的团队规范要不要遵守?没有写在文档里的性能底线,要不要了解?
这些可不是什么虚无缥缈的东西,做个“优化排序算法”吧,代码生成给出快排实现就结束;而SWE要考虑:为什么前任用冒泡排序(历史)?会不会破坏报表模块的调用(依赖)?是否符合内存限制(约束)?
看似只是一个简单的需求,实际上已经给智能体上了无数道枷锁,对模型的能力要求也是高了不止一个level。
你以为这就完了吗?
在SWE的开发中,每个决策都涉及多维度的取舍,需求、环境和工具链都在发生持续的变化,任何修改都会产生涟漪效应,智能体与开发者或者工程师进行多轮、深入、澄清性对话,最好还是能主动提问以消除需求歧义。
现在知道,昆仑万维想要做仓库级代码修复能力的模型,有多不容易了吧。
现有SWE数据集的三大致命缺陷
这是对智能体模型的工程实践水平与系统性思维能力的全面考验,想要训练出足够优秀的模型,困难究竟卡在哪里了呢?
在大量的从业者看来,SWE模型训练最大的bug,还是出在数据集上。宣称能驱动智能体执行软件工程任务的大模型,其能力基石在于训练数据。
尽管已有不少工作聚焦于SWE任务并收集了相关的数据集,但当前的主流数据集仍存在三大核心问题,严重阻碍了该领域的进一步发展。它们如同沉重的锁链,将模型的潜力死死禁锢在实验室的牢笼中,使其难以突破理论演示的边界,迈向真实的工程战场。
第一大问题,缺乏可执行环境与验证机制。
已有开源数据(如 SWE-bench-extra、SWE-Fixer)通常缺乏环境或单元测试来验证数据正确性,导致生成的修复难以验证。
第二大问题,高质量训练数据稀缺。
尽管某些数据集规模较大(如 SWE-Dev、SWE-Gym),但缺乏经过严格验证的训练样本,公开可用的高质量数据极为有限,导致开源模型在 SWE 任务上落后于闭源模型。
第三大问题:数据规模法则适用性不明确。
相较于自然语言领域中的任务,SWE任务现有的公开训练数据体量较小,尚无法有效验证数据扩展是否能带来模型能力的持续增长。
唯有跨越这数据鸿沟,智能体才有望从“代码补全工具”蜕变为值得信赖的“工程伙伴”。
谁能想到,这个众多国内外公司都无法取得突破的问题,竟然就被昆仑万维这家国内的AI公司给实现了呢?
Skywork-SWE-32B的破局之道
为什么是昆仑万维?可能不少人会有这样的疑问。
昆仑万维作为中国AI开源领域的先行者,自2022年底发布并开源“昆仑天工”AIGC全系列算法模型以来,持续深耕AGI,既有着技术突破,又有全面前瞻的生态布局。
2023年昆仑万维就开源了130亿参数模型Skywork-13B系列,配套发布当时最大的中文数据集Skypile-150B(600GB),2024年开源全球首个支持单台RTX 4090服务器推理的千亿MoE稀疏模Skywork-MoE,推理成本降低3倍,性能接近70B稠密模型。前段时间中国大陆首个对标OpenAI deep research的天工超级智能体,也是昆仑万维推出的agent产品。
既有技术能力,又有工程思维,能够做出来仓库级代码修复能力的智能体模型,也是顺理成章了。
为了Skywork-SWE-32B,昆仑万维团队构建了一套自动化、结构化、可复现的SWE数据收集与验证流程,共分为3个阶段、9个步骤,最终构建出超1万条高质量任务实例、8千条多轮交互的轨迹,为模型训练提供坚实基础。
构建万级可验证闭环数据集

图中显示,三个阶段分别为,A.数据采集与预筛选、B.基于执行的验证机制、C.智能体轨迹生成,每个阶段又有主要的三个步骤。
数据采集与预筛选阶段,先通过 GitHub API 抓取超过 15 万个开源仓库的元信息,处理后最终获得 8,472 个有效仓库的元信息,再通过收集与任务初筛构建出初始的146,568个任务样本,最后安装验证保留23,389个任务样本。
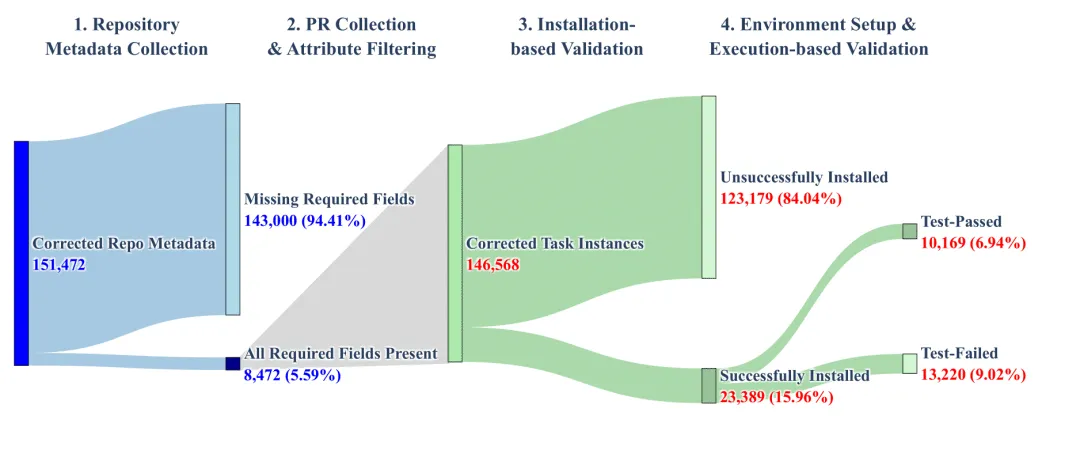
数据构建过程中各个阶段数据样本量变化图
基于执行的验证机制阶段, 统一命令生成,Docker环境构建,最后进行单元测试验证。
最后一个智能体轨迹生成阶段,首先要对每个任务执行最多100轮交互,完成智能体轨迹生成,Patch级验证,最终累计收集8,209条高质量、长上下文、多轮交互的验证通过轨迹,构建训练样本库。

Skywork-SWE数据集的GitHub仓库词云图
这样构建的Skywork-SWE数据集,在任务数量与代码覆盖广度上远超现有同类数据集(如SWE-Gym Lite与SWE-bench Verified),不仅涵盖如 Pydantic、SQLGlot、DVC 等主流开源GitHub项目,还包含大量中小型仓库,为大模型提供了丰富、多样且贴近实际的软件工程任务样本,持续推动智能体模型的能力演进。
系统性验证软件工程Scaling Law的机会
基于Skywork-SWE数据集的高质量智能体轨迹,选用目前最具自主性的开源OpenHands框架,昆仑万维团队训练了Skywork-SWE-32B模型。看这款模型的参数和得分,真给开源界整了个大活儿。
Skywork-SWE-32B基于开源OpenHands Agent框架,实现了38.0% pass@1的准确率,在32B规模的开源代码智能体中达到了当前最优水平。
这说明什么?同尺寸模型里最能打,没有之一!
更为关键的是,实验结果进一步表明:Scaling Law在SWE任务上也成了。
以前我们说,跟语言任务不一样,SWE任务现有的公开训练数据体量较小,尚无法有效验证数据扩展是否能带来模型能力的持续增长。
但是现在,这个论点被昆仑万维证实了。
只要训练数据规模能够持续扩展,模型性能就能持续提升,在软件工程任务中,这句话一样有效,一样有用。
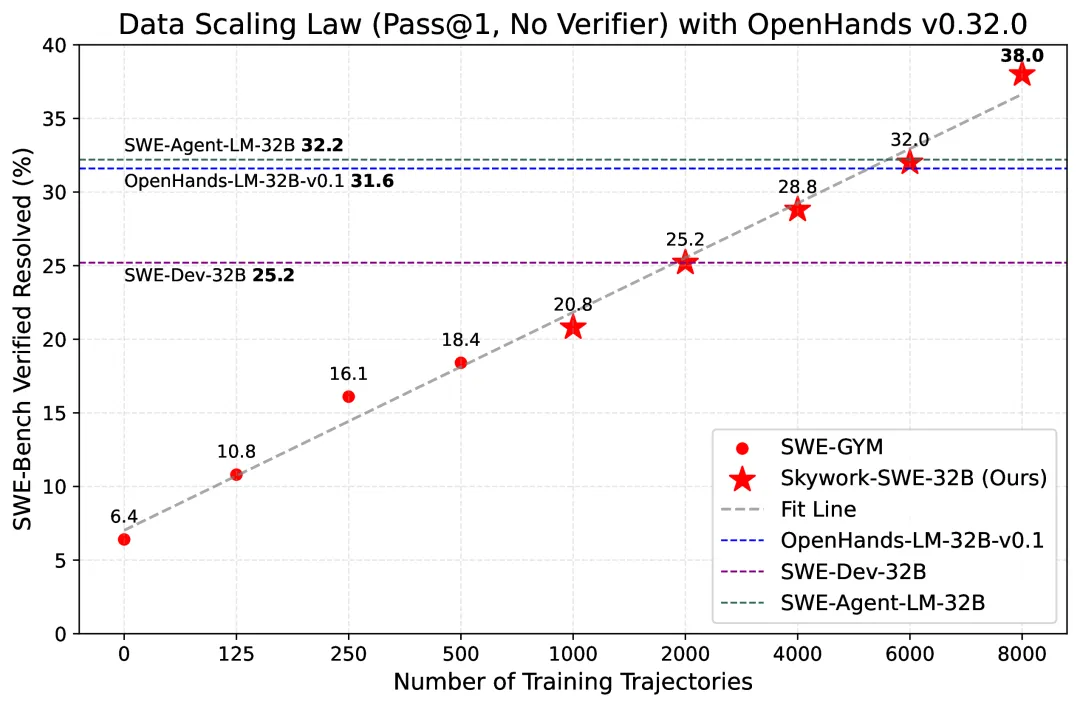
38.0% 性能就是Skywork-SWE-32B的极限了吗?不是。
加上测试时扩展(Test-Time Scaling, TTS),模型性能直接原地起飞到47.0%。单枪匹马干翻所有同框架模型不说,甚至把671B参数的DeepSeek-V3-0324都给卷了,领先整整8.2个百分点,小模型打败十倍大模型的经典场景复刻。
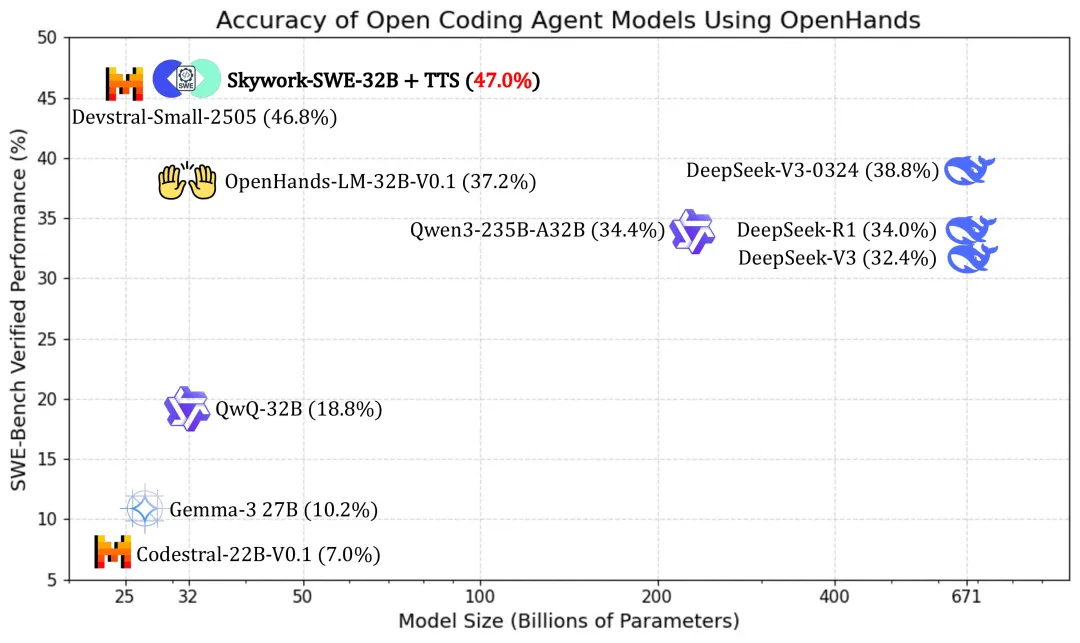
在这个领域,Claude和OpenAI的系列闭源模型才是王者。比起来的话:
加了TTS,Skywork-SWE-32B 显著超越了GPT-4.1-mini(23.86%)、 Claude 3.5 HaiKu(40.6%)和 OpenAI-o1-preview (41.3%),并且领先于Claude v3.5(46.0%)。
高性能的开源模型,对于企业想私有化部署特别有吸引力。
它们不仅保障了核心数据在本地环境的安全可控,规避了隐私泄露风险,更赋予了企业根据自身业务需求深度定制和优化的自由,无需持续支付高昂的API费用。
开源模型DeepSeek-V3 就曾凭借其强大的性能成为不少企业和组织的首选,Skywork-SWE-32B对于有SWE需求的企业来说,同样有着足够的吸引力。
推动软件开发范式新进化
今年2月5日,OpenAI首席执行官Sam Altman在公开场合谈到了AI如何改变软件工程,他的说法是,“到2025年底,软件工程将发生翻天覆地的变化。这不仅意味着开发效率的大幅提升,还可能对网络安全产生深远的影响。”
这个预言正在被实现。
AI对软件开发范式的重构已从“工具辅助”阶段迈入“智能体主导”的新时代,推动开发流程、协作模式、技术门槛与行业标准的系统性变革。
Skywork-SWE-32B的出现,是这个变化趋势中的特殊时刻。这不仅是技术上的升级,更是开发哲学的根本转向。
高质量且可执行验证的数据是提升代码智能体模型性能的关键瓶颈。系统化的数据扩展策略将在推动开源模型性能突破中发挥关键作用。
智能体开始承担需求分析、架构设计等核心决策任务,推动开发流程从线性流水线向动态自适应演进。传统“人主导工具”的协作模式正被颠覆。
昆仑万维发布的Skywork-SWE正在进一步拓展多编程语言支持以覆盖更广泛的开发场景,并探索融合运行时测试反馈的强化学习机制,为构建真正具备智能软件开发能力的大语言模型奠定坚实基础。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“32B模型横扫SWE任务,这款代码智能体模型有点东西”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~