
清华上交大研究:RL助大模型套公式,难提升真推理: 清华和上交的最新论文中,上演了一场 “学术打假” 的戏码。文中研究者们对当前 “纯 RL 有利于提升模型推理能力” 的主……
哈喽!伙伴们,我是小智,你们的AI向导。欢迎来到每日的AI学习时间。今天,我们将一起深入AI的奇妙世界,探索“清华上交大研究:RL助大模型套公式,难提升真推理”,并学会本篇文章中所讲的全部知识点。还是那句话“不必远征未知,只需唤醒你的潜能!”跟着小智的步伐,我们终将学有所成,学以致用,并发现自身的更多可能性。话不多说,现在就让我们开始这场激发潜能的AI学习之旅吧。

清华上交大研究:RL助大模型套公式,难提升真推理:
清华和上交的最新论文中,上演了一场 “学术打假” 的戏码。文中研究者们对当前 “纯 RL 有利于提升模型推理能力” 的主流观点提出了相反的意见。
通过一系列实验,他们证明引入强化学习的模型在某些任务中的表现,竟然不如未使用强化学习的模型。
论文批判性地探讨了 RLVR 在提升 LLM 推理能力方面的作用,尤其是在赋予模型超越自身原有能力方面,效果可能并非像人们普遍认为的那样“无懈可击”。

消息一出,网友们纷纷下场站队。
有人认为这篇文章抓住了 RL 自身的漏洞,虽然提高了采样效率,但它似乎在推理方面存在不足,未来我们需要新的方法来释放 LLM 的全部潜力。

也有人表示,或许强化学习实际上限制了模型开发新推理行为的能力。真正的推理增强可能需要蒸馏等方法。

质疑声之外,RL 的追随者也在为“信仰”发声:这种说法是错的,验证远比生成简单的多。

也有网友表示,这更像是奖励结构的缺陷,而非 RLVR 本身的问题。如果用二元奖励结构,出现这种情况可以理解。但我们可以调整奖励结构来缓解这个问题,甚至还能激励更好的推理。

1.强化学习:擅长加速,不擅长开路
实验中,研究人员在三个具有代表性的领域进行了实验,来评估 RLVR 对基础模型和 RLVR 模型的推理能力边界的影响。
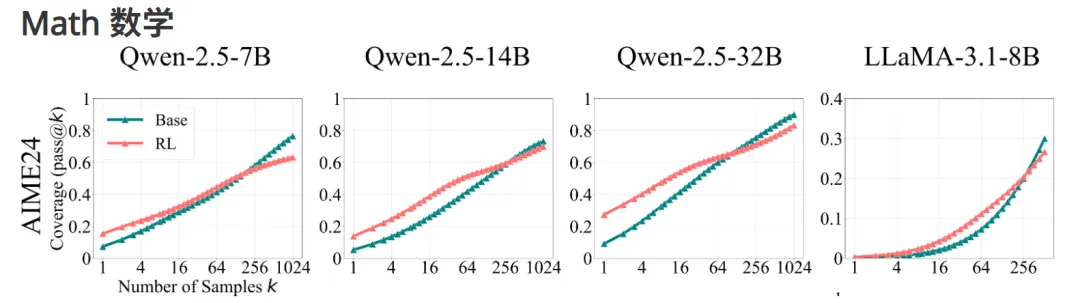
在数学任务实验中,研究团队在 GSM8K、MATH500 和 AIME24 等基准上评估了多个大语言模型系列(如 Qwen-2.5 和 LLaMA-3.1)及其经过 RL 训练的变体。他们通过分析 pass@k 曲线,比较了基础模型与 RL 模型的表现,发现虽然 RL 在低 k 值下提升了模型的准确性,但在高 k 情况下却显著降低了问题的覆盖范围。
此外,研究者还手动审查了模型生成的 CoT(Chain of Thought)推理过程,以确认正确答案是推理得出而非纯属运气。最后,他们还研究了采用 Oat-Zero 方法训练的模型,并对数据集进行了过滤,剔除容易猜测的问题,从而聚焦于更具挑战性的样本。
整体结果显示,尽管 RL 能在初始准确率上带来提升,基础模型在推理覆盖率方面仍表现更为稳健。
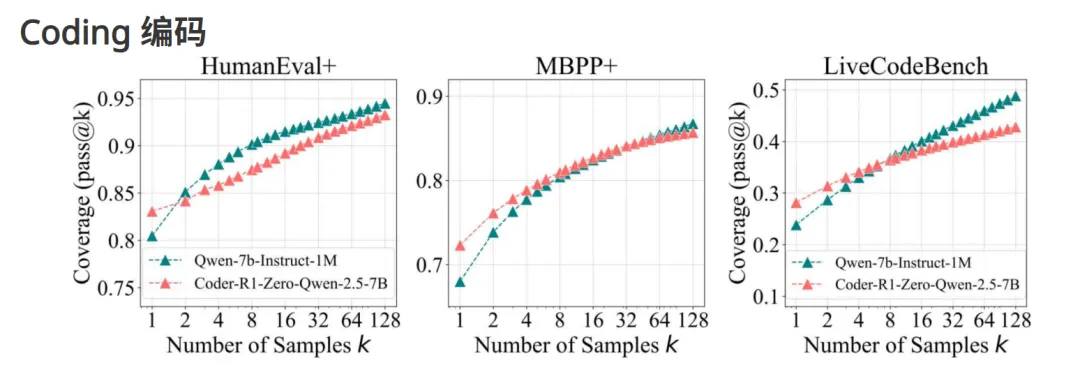
在编码任务实验中,研究团队在 LiveCodeBench、HumanEval+ 和 MBPP+ 等基准上评估了源自 Qwen2.5-7B-Instruct-1M 的 RLVR 训练模型 CodeR1-Zero-Qwen2.5-7B。他们通过 pass@k 指标来衡量性能,并根据预定义的测试用例评估模型的正确性。
结果显示,RLVR 提升了单样本 pass@1 的分数,但在较高采样数(k = 128)时,模型的覆盖率有所下降。与此相比,原始模型在较大 k 值下表现出了持续改进的潜力,而 RLVR 的性能则趋于平稳。这表明,尽管 RLVR 提高了模型的确定性准确性,但在探索多样性方面存在一定的限制。
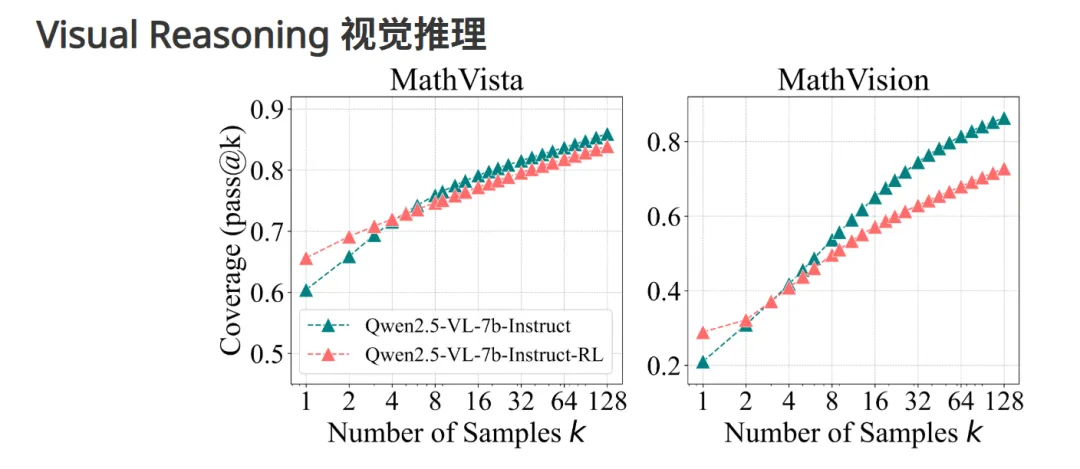
在视觉推理实验中,研究团队在过滤后的视觉推理基准(MathVista 和 MathVision)上评估了 Qwen-2.5-VL-7B,删除了多项选择题,聚焦于稳健的问题解决能力。RLVR 在视觉推理任务中的表现提升与数学和编码基准中的改进相一致,表明原始模型已能够解决广泛的问题,即便是在多模态任务中也同样如此。
跨领域的一致性表明,RLVR 提升了模型的推理能力,同时并未从根本上改变模型的问题解决策略。
2.推理能力的边界
使用单次通过的成功率或平均核采样衡量模型推理能力边界的传统指标存在重要缺陷。如果模型在少数几次尝试后未能解决难题,但却本可以通过更多次的采样获得成功,此时其真实推理潜力可能会被低估。
如果为基础模型投入大量采样资源,它的性能能否与经过强化学习训练的模型相匹配?
为精准评估大语言模型的推理能力边界,研究团队将代码生成领域常用的pass@k指标拓展至所有可验证奖励的任务。针对一个问题,从模型中采样k个输出,若至少一个样本通过验证,该问题的pass@k 值为1,否则为0。数据集上的平均 pass@k 值反映了模型在 k 次试验内可解决的数据集问题比例,能严格评估 LLM 的推理能力覆盖范围。
直接按问题采样k个输出计算pass@k可能导致高方差。他们采用无偏估计法,对评估数据集D中的每个问题生成 n 个样本(n ≥ k),统计正确样本数。对于使用编译器和预定义单元测试用例作为验证器的编码任务,pass@k 值能准确反映模型是否能解决问题。
然而,随着 k 增大,数学问题中 “黑客” 行为可能凸显,即模型可能生成错误的推理过程,却在多次采样中偶然得出正确答案,这一情况常被以往指标忽视。为此,他们筛选出易被 “黑客” 攻克的问题,并手动检查部分模型输出的 CoT 正确性。结合这些措施,他们严格评估了 LLM 的推理能力极限。
3.当强化学习不再“强化”
清华与上交的这篇论文,为当前业界广泛推崇的强化学习范式敲响了警钟。让我们不得不重新思考强化学习在大模型训练流程中的真正角色。
我们也不能将模型的“能力”与“效率”混为一谈。能力,指的是模型是否拥有解决某类问题的潜质与逻辑链条;效率,则是在给定的能力范围内,模型能以多快、多稳、多省资源的方式得出答案。
强化学习或许确实能够提升模型在已有能力基础上的输出表现(比如在低采样次数下更快给出正确答案),但这并不代表它为模型带来了新的推理路径或更复杂问题的解决能力。相反,在高采样场景中,RL 带来的“收敛性”可能牺牲了答案的多样性,从而错失了解决更多难题的机会。
强化学习更像是一种能力调控器,而非能力创造器。它可以让模型更擅长做已经能做的事,但难以让模型做出“原本不会的事”。正因如此,若将 RL 简单视为提升模型通用智能的万能钥匙,未免过于乐观。接下来的技术路线,可能需要更多关注基础模型在表示能力、知识组织与推理路径构建等方面的设计,而非过度依赖下游的策略微调。
总的来说,这项研究的意义不在于“RL 无用”的结论,而在于它揭示了在过热预期背后,强化学习真正适用的边界。这或许会促使研究者和企业在制定大模型优化方案时,回归问题本质,用更清晰的标准衡量“能力的提升”究竟意味着什么。
嘿,伙伴们,今天我们的AI探索之旅已经圆满结束。关于“清华上交大研究:RL助大模型套公式,难提升真推理”的内容已经分享给大家了。感谢你们的陪伴,希望这次旅程让你对AI能够更了解、更喜欢。谨记,精准提问是解锁AI潜能的钥匙哦!如果有小伙伴想要了解学习更多的AI知识,请关注我们的官网“AI智研社”,保证让你收获满满呦!
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 















还没有评论呢,快来抢沙发~